Abstract Prostate cancer is the most common malignancy affecting men and thesecond-leading cause of cancer death in the US. To detect and classify the risk of prostate cancer, doctors perform screening of prostate-specific antigen (PSA) levels. In this Thesis we want to improve thisrisk classification with unsupervised machine learning methods, as thelabels of cancer or no cancer may not reflect the truth; given that canceris only considered as such after confirmation by biopsy and thus possi-bly leaving some patients with cancer with the wrong label.
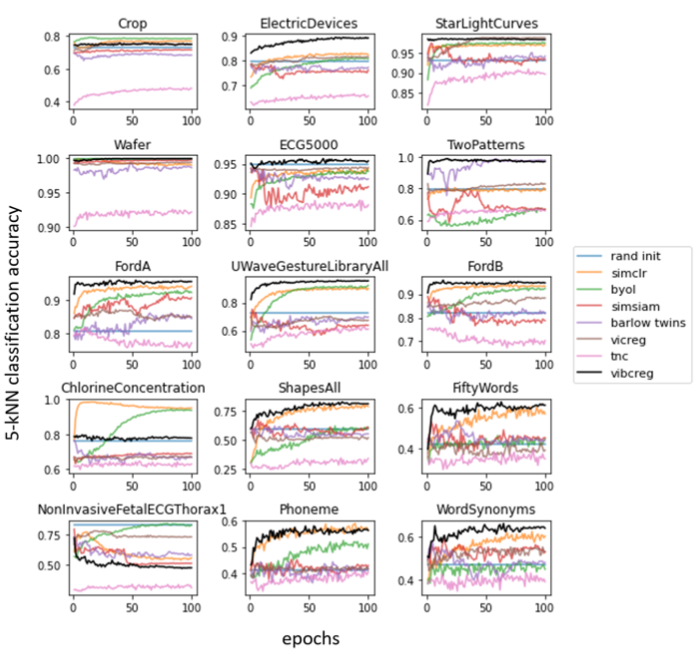
Abstract Self-supervised learning (SSL) has had great success in both com- puter vision and natural language processing. These approaches often rely on cleverly crafted loss functions and training setups to avoid feature collapse. In this study, the effectiveness of mainstream SSL frameworks from computer vision and some SSL frameworks for time series are evaluated on the UCR, UEA and PTB-XL datasets, and we show that computer vision SSL frameworks can be effective for time series.
Abstract This paper presents a novel sampling scheme for masked non-autoregressive generative modeling. We identify the limitations of TimeVQVAE, MaskGIT, and Token-Critic in their sampling processes, and propose Enhanced Sampling Scheme (ESS) to overcome these limitations. ESS explicitly ensures both sample diversity and fidelity, and consists of three stages: Naive Iterative Decoding, Critical Reverse Sampling, and Critical Resampling. ESS starts by sampling a token set using the naive iterative decoding as proposed in MaskGIT, ensuring sample diversity.
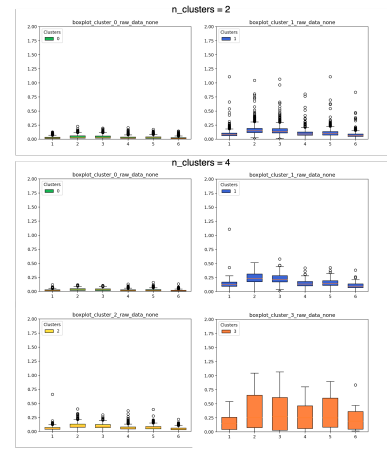
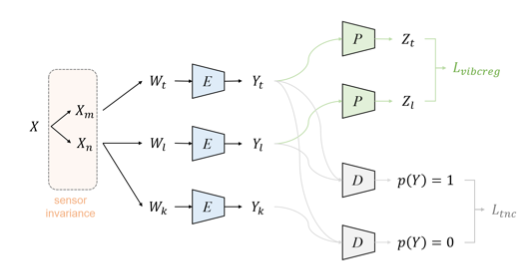
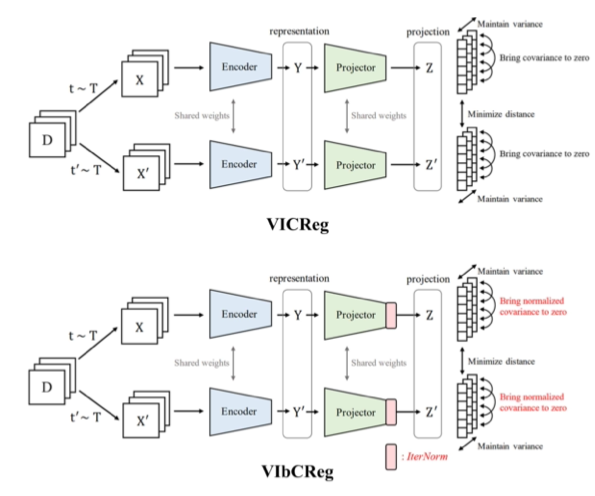
Abstract Self-supervised learning for image representations has recently had many breakthroughs with respect to linear evaluation and fine-tuning evaluation. These approaches rely on both cleverly crafted loss functions and training setups to avoid the feature collapse problem. In this paper, we improve on the recently proposed VICReg paper, which introduced a loss function that does not rely on specialized training loops to converge to useful representations. Our method improves on a covariance term proposed in VICReg, and in addition we augment the head of the architecture by an IterNorm layer that greatly accelerates convergence of the model.